Потоки в Python
В этой статье вы узнаете, как использовать модуль threading Python для разработки многопоточных программ.
Однопоточные программы
Давайте начнём с простой программы:
from time import sleep, perf_counter
def task():
print('Начали выполнение задачи...')
sleep(1)
print('Выполнено')
start_time = perf_counter()
task()
task()
end_time = perf_counter()
print(f'Выполнение заняло {end_time- start_time: 0.2f} секунд.')Как это работает
1. Мы импортировали функции sleep() и perf_counter() из модуля time:
from time import sleep, perf_counter
2. Далее создали функцию, которая выполняется за одну секунду.
def task():
print('Начали выполнение задачи...')
sleep(1)
print('Выполнено')3. Затем получили значение счетчика производительности с помощью функции perf_counter():
start_time = perf_counter() 4. Дважды вызвали функцию task():
task()
task()5. Получили значение счетчика производительности с помощью функции perf_counter():
end_time = perf_counter()6. Вывели время, необходимое для завершения выполнения функции task() дважды:
print(f'Выполнение заняло {end_time- start_time: 0.2f} секунд.')
Вывод
Начали выполнение задачи...
Выполнено
Начали выполнение задачи...
Выполнено
Выполнение заняло 2.00 секунд.
Как и следовало ожидать, выполнение программы занимает около двух секунд. Если вызвать функцию task() 10 раз, то на выполнение займет примерно 10 секунд.
На следующей диаграмме показано, как работает программа:
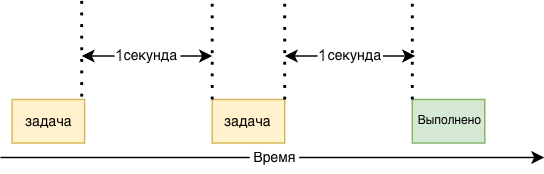
Сначала выполняется функция task(), и она «засыпает» на одну секунду. Затем она выполняется во второй раз и также «засыпает» еще на одну секунду. Наконец, программа завершается.
Когда функция task() вызывает функцию sleep(), процессор простаивает. Другими словами, ЦП ничего не делает, что неэффективно с точки зрения использования ресурсов.
В этой программе есть один процесс с одним потоком, который называется главным потоком. Поскольку программа имеет только один поток, она называется однопоточной.
Модуль threading для мультипоточных программ
Чтобы создать многопоточную программу, необходимо использовать Python-модуль threading.
1. Импортируем класс Thread из модуля threading:
from threading import Thread2. Создадим новый поток, инстанцировав экземпляр класса Thread:
new_thread = Thread(target=fn,args=args_tuple)
Thread() принимает множество параметров. Мы использовали основные из них:
target: указывает функцию (fn) для выполнения в новом потоке.args: указывает аргументы функции (fn). Аргумент args представляет собой кортеж.
3. Запустим поток, вызвав метод start() экземпляра Thread:
new_thread.start()Если вы хотите дождаться завершения потока в главном потоке, вы можете вызвать метод join():
new_thread.join()После вызова метода join() главный поток будет ждать завершения второго потока.
Следующая программа иллюстрирует использование модуля threading:
from time import sleep, perf_counter
from threading import Thread
def task():
print('Начинаем выполнение задачи...')
sleep(1)
print('Выполнено')
start_time = perf_counter()
# создаем два новых потока
t1 = Thread(target=task)
t2 = Thread(target=task)
# запускаем потоки
t1.start()
t2.start()
# ждем, когда потоки выполнятся
t1.join()
t2.join()
end_time = perf_counter()
print(f'Выполнение заняло {end_time- start_time: 0.2f} секунд.')Как это работает
1. Создаем два новых потока:
t1 = Thread(target=task)
t2 = Thread(target=task)2. Запускаем оба потока, вызвав метод start():
t1.start()
t2.start()3. Ждем, пока потоки выполнятся:
t1.join()
t2.join()4. Выводим время выполнения:
print(f'Выполнение заняло {end_time- start_time: 0.2f} секунд.')Вывод
Начинаем выполнение задачи...
Начинаем выполнение задачи...
Выполнено
Выполнено
Выполнение заняло 1.00 секунд.
Когда программа будет выполнена, в ней будет три потока: главный поток, созданный интерпретатором Python, и два потока, созданные программой.
Как хорошо видно из вывода, на выполнение программы ушла одна секунда вместо двух.
На следующей диаграмме показано, как выполняются потоки:
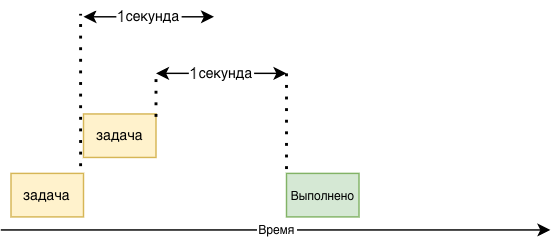
Передача аргументов в потоки
Следующая программа показывает, как передать аргументы в функцию, назначенную потоку:
from time import sleep, perf_counter
from threading import Thread
def task(id):
print(f'Начинаем выполнение задачи {id}...')
sleep(1)
print(f'Задача {id} выполнена')
start_time = perf_counter()
# создаем и запускаем 10 потоков
threads = []
for n in range(1, 11):
t = Thread(target=task, args=(n,))
threads.append(t)
t.start()
# ждем, когда потоки выполнятся
for t in threads:
t.join()
end_time = perf_counter()
print(f'Выполнение заняло {end_time- start_time: 0.2f} секунд.')Как это работает
1. Создаем функцию task(), принимающую аргумент id:
def task(id):
print(f'Начинаем выполнение задачи {id}...')
sleep(1)
print(f'Задача {id} выполнена')2. Создаем 10 новых потоков и передать каждому из них id. Список потоков используется для отслеживания всех вновь созданных потоков:
threads = []
for n in range(1, 11):
t = Thread(target=task, args=(n,))
threads.append(t)
t.start()Примечание. Если вы вызовете метод
join()внутри цикла, программа будет ждать завершения первого потока перед запуском следующего.
3. Дожидаемся завершения работы всех потоков, вызвав метод join():
for t in threads:
t.join()Вывод
Начинаем выполнение задачи 1...
Начинаем выполнение задачи 2...
Начинаем выполнение задачи 3...
Начинаем выполнение задачи 4...
Начинаем выполнение задачи 5...
Начинаем выполнение задачи 6...
Начинаем выполнение задачи 7...
Начинаем выполнение задачи 8...
Начинаем выполнение задачи 9...
Начинаем выполнение задачи 10...
Задача 10 выполнена
Задача 8 выполнена
Задача 1 выполнена
Задача 6 выполнена
Задача 7 выполнена
Задача 9 выполнена
Задача 3 выполнена
Задача 4 выполнена
Задача 2 выполнена
Задача 5 выполнена
Выполнение заняло 1.02 секунд.
На все 10 потково ушло 1,02 секунды.
Примечание. Обратите внимание, что потоки выполняются не по порядку от 1 до 10.
Когда стоит использовать потоки
В предыдущей статье «Процессы и потоки» мы познакомились с двумя типами задач: связанные с вводом-выводом (I/O-bound) и связанные с процессором (CPU-bound).
Потоки оптимизированы для задач, связанных с вводом-выводом. Например: сетевые запросы, соединения с базами данных, ввод/вывод файлов.
Используем потоки на практике
Предположим, что у нас есть список текстовых файлов в папке, например, C:/temp/. Мы хотим заменить текст во всех файлах.
Однопоточная программа
Вот однопоточная программа, которая заменяет подстроку в текстовых файлах:
from time import perf_counter
def replace(filename, substr, new_substr):
print(f'Обрабатываем файл {filename}')
# получаем содержимое файла
with open(filename, 'r') as f:
content = f.read()
# заменяем substr на new_substr
content = content.replace(substr, new_substr)
# записываем данные в файл
with open(filename, 'w') as f:
f.write(content)
def main():
filenames = [
'c:/temp/test1.txt',
'c:/temp/test2.txt',
'c:/temp/test3.txt',
'c:/temp/test4.txt',
'c:/temp/test5.txt',
'c:/temp/test6.txt',
'c:/temp/test7.txt',
'c:/temp/test8.txt',
'c:/temp/test9.txt',
'c:/temp/test10.txt',
]
for filename in filenames:
replace(filename, 'ids', 'id')
if __name__ == "__main__":
start_time = perf_counter()
main()
end_time = perf_counter()
print(f'Выполнение заняло {end_time- start_time :0.2f} секунд.')
Вывод
Выполнение заняло 0.16 секунд.
Многопоточная программа
А вот программа, которая делает то же самое, но с помощью нескольких потоков:
from threading import Thread
from time import perf_counter
def replace(filename, substr, new_substr):
print(f'Обрабатываем файл {filename}')
# получаем содержимое файла
with open(filename, 'r') as f:
content = f.read()
# заменяем substr на new_substr
content = content.replace(substr, new_substr)
# записываем данные в файл
with open(filename, 'w') as f:
f.write(content)
def main():
filenames = [
'c:/temp/test1.txt',
'c:/temp/test2.txt',
'c:/temp/test3.txt',
'c:/temp/test4.txt',
'c:/temp/test5.txt',
'c:/temp/test6.txt',
'c:/temp/test7.txt',
'c:/temp/test8.txt',
'c:/temp/test9.txt',
'c:/temp/test10.txt',
]
# создаем потоки
threads = [Thread(target=replace, args=(filename, 'id', 'ids'))
for filename in filenames]
# запускаем потоки
for thread in threads:
thread.start()
# ждем завершения потоков
for thread in threads:
thread.join()
if __name__ == "__main__":
start_time = perf_counter()
main()
end_time = perf_counter()
print(f'Выполнение заняло {end_time- start_time :0.2f} секунд.')
Вывод
Обрабатываем файл c:/temp/test1.txt
Обрабатываем файл c:/temp/test2.txt
Обрабатываем файл c:/temp/test3.txt
Обрабатываем файл c:/temp/test4.txt
Обрабатываем файл c:/temp/test5.txt
Обрабатываем файл c:/temp/test6.txt
Обрабатываем файл c:/temp/test7.txt
Обрабатываем файл c:/temp/test8.txt
Обрабатываем файл c:/temp/test9.txt
Обрабатываем файл c:/temp/test10.txt
Выполнение заняло 0.02 секунд.
Как вы можете видеть из вывода, многопоточная программа работает намного быстрее.
Что нужно запомнить
- Используйте модуль
threadingдля создания многопоточной программы. - Используйте
Thread(function, args)для создания нового потока. - Вызовите метод
start()классаThread, чтобы запустить поток. - Вызовите метод
join()классаThread, чтобы дождаться завершения потока в главном потоке. - Используйте потоки только для программ, связанных с обработкой ввода-вывода.