Хеш-таблицы
В этой статье вы познакомитесь с хэш-таблицами и увидите примеры их реализации в Cи, C++, Java и Python.
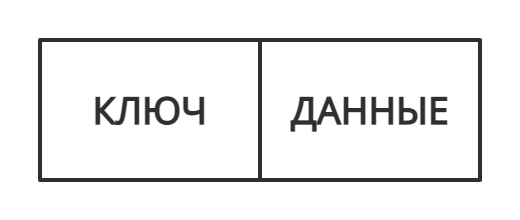
Хеш-таблица — это структура данных, в которой все элементы хранятся в виде пары ключ-значение, где:
- ключ — уникальное число, которое используется для индексации значений;
- значение — данные, которые с этим ключом связаны.
Хеширование (хеш-функция)
В хеш-таблице обработка новых индексов производится при помощи ключей. А элементы, связанные с этим ключом, сохраняются в индексе. Этот процесс называется хешированием.
Пусть k — ключ, а h(x) — хеш-функция.
Тогда h(k) в результате даст индекс, в котором мы будем хранить элемент, связанный с k.
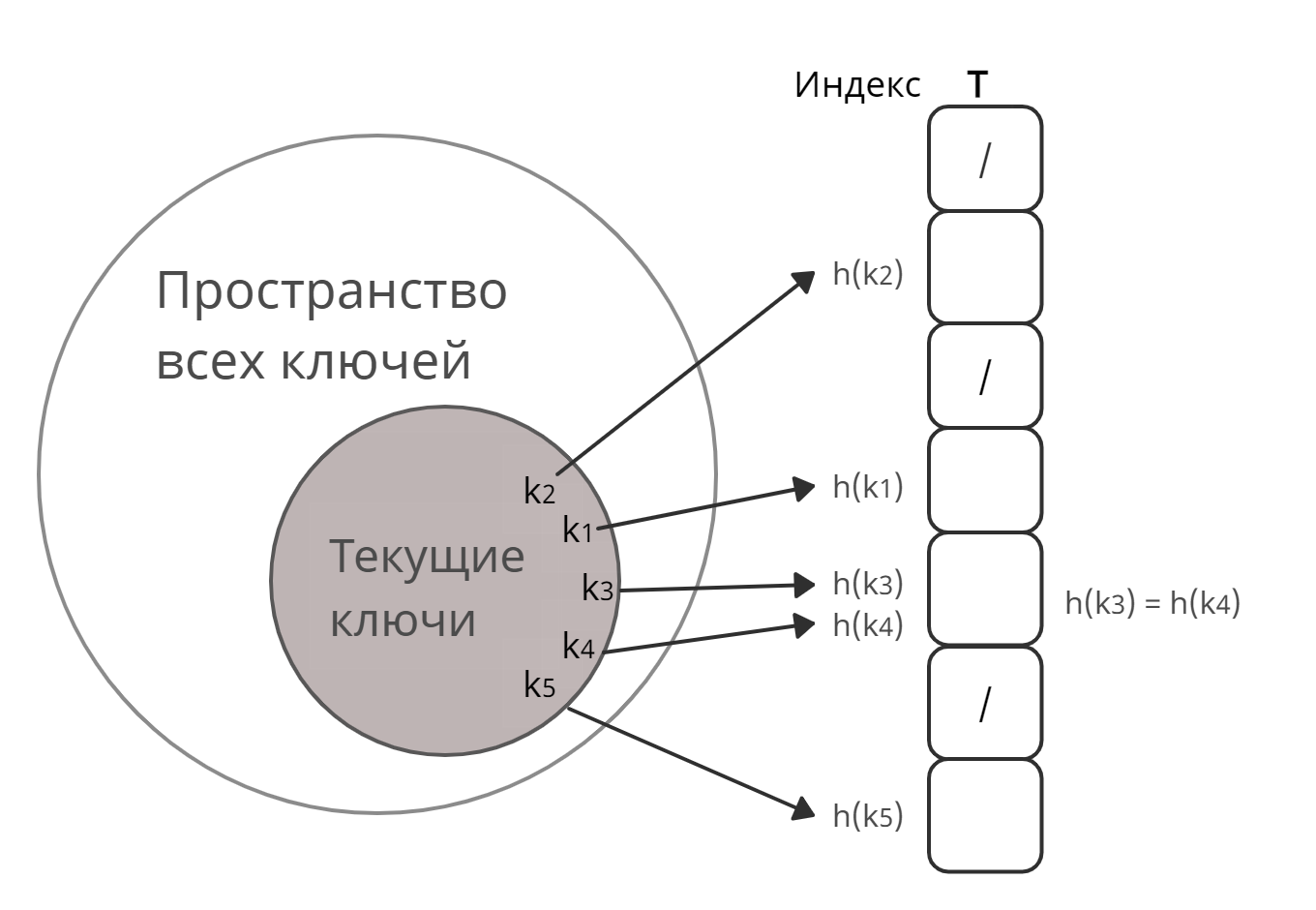
Коллизии
Когда хеш-функция генерирует один индекс для нескольких ключей, возникает конфликт: неизвестно, какое значение нужно сохранить в этом индексе. Это называется коллизией хеш-таблицы.
Есть несколько методов борьбы с коллизиями:
- метод цепочек;
- метод открытой адресации: линейное и квадратичное зондирование.
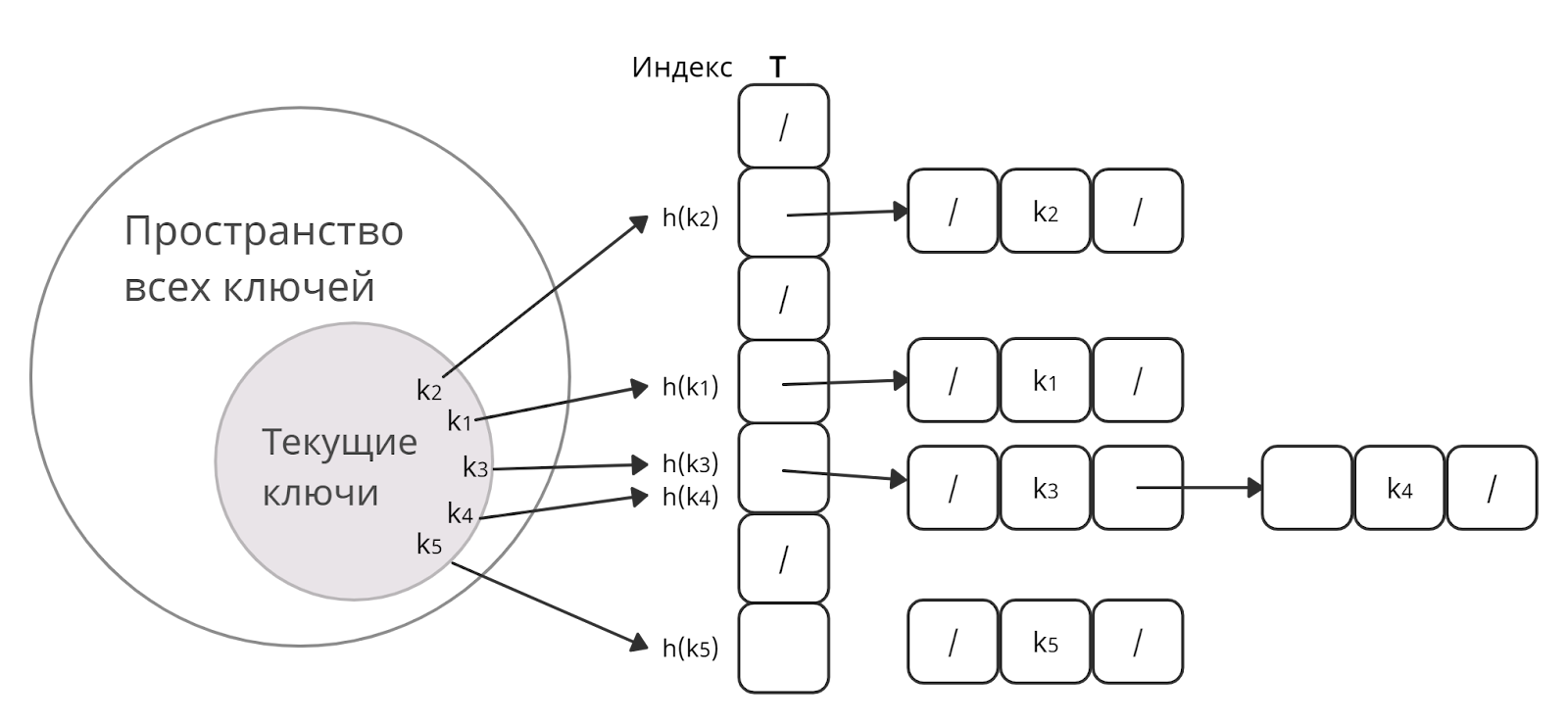
1. Метод цепочек
Суть этого метода проста: если хеш-функция выделяет один индекс сразу двум элементам, то храниться они будут в одном и том же индексе, но уже с помощью двусвязного списка.
Если j — ячейка для нескольких элементов, то она содержит указатель на первый элемент списка. Если же j пуста, то она содержит NIL.
Псевдокод операций
chainedHashSearch(T, k)
return T[h(k)]
chainedHashInsert(T, x)
T[h(x.key)] = x
chainedHashDelete(T, x)
T[h(x.key)] = NIL 2. Открытая адресация
В отличие от метода цепочек, в открытой адресации несколько элементов в одной ячейке храниться не могут. Суть этого метода заключается в том, что каждая ячейка либо содержит единственный ключ, либо NIL.
Существует несколько видов открытой адресации:
a) Линейное зондирование
Линейное зондирование решает проблему коллизий с помощью проверки следующей ячейки.
h(k, i) = (h′(k) + i) mod m,
где
i = {0, 1, ….}h'(k)— новая хеш-функция
Если коллизия происходит в h(k, 0), тогда проверяется h(k, 1). То есть значение i увеличивается линейно.
Проблема линейного зондирования заключается в том, что заполняется кластер соседних ячеек. Это приводит к тому, что при вставке нового элемента в хеш-таблицу необходимо проводить полный обход кластера. В результате время выполнения операций с хеш-таблицами увеличивается.
b) Квадратичное зондирование
Работает оно так же, как и линейное — но есть отличие. Оно заключается в том, что расстояние между соседними ячейками больше (больше одного). Это возможно благодаря следующему отношению:
h(k, i) = (h′(k) + c1i + c2i2) mod m,
где
c1иc2— положительные вспомогательные константы,i = {0, 1, ….}
c) Двойное хэширование
Если коллизия возникает после применения хеш-функции h(k), то для поиска следующей ячейки вычисляется другая хеш-функция.
h(k, i) = (h1(k) + ih2(k)) mod m
«Хорошие» хеш-функции
«Хорошие» хеш-функции не уберегут вас от коллизий, но, по крайней мере, сократят их количество.
Ниже мы рассмотрим различные методы определения «качества» хэш-функций.
1. Метод деления
Если k — ключ, а m — размер хеш-таблицы, то хеш-функция h() вычисляется следующим образом:
h(k) = k mod m
Например, если m = 10 и k = 112, то h(k) = 112 mod 10 = 2. То есть значение m не должно быть степенью 2. Это связано с тем, что степени двойки в двоичном формате — 10, 100, 1000… При вычислении k mod m мы всегда будем получать p-биты низшего порядка.
если m = 2², k = 17, тогда h(k) = 17 mod 2² = 10001 mod 100 = 01
если m = 2³, k = 17, тогда h(k) = 17 mod 2³ = 10001 mod 1000 = 001
если m = 2⁴, k = 17, тогда h(k) = 17 mod 2⁴ = 10001 mod 10000 = 0001
если m = 2ᵖ, тогда h(k) = p биты порядком ниже, чем mПосмотрите на метод деления в действии. Блок-схема ниже вычисляет h(k) = k mod m для двух ключей при размере таблицы m = 10 и проверяет, не попали ли они в одну ячейку. Введите, например, ключи 112 и 42 — а затем попробуйте подобрать пару ключей без коллизии.
m = 10
k1 = int(input())
k2 = int(input())
h1 = k1 % m
h2 = k2 % m
print("Ключ", k1, "→ ячейка", h1)
print("Ключ", k2, "→ ячейка", h2)
if h1 == h2:
print("Коллизия! Ключи претендуют на одну ячейку")
else:
print("Коллизии нет")Ключи 112 и 42 дают один и тот же индекс 2 — это и есть коллизия, которую придется разрешать методом цепочек или открытой адресацией.
2. Метод умножения
h(k) = ⌊m(kA mod 1)⌋,
где
kA mod 1отделяет дробную частьkA;⌊ ⌋округляет значение;A— произвольная константа, значение которой должно находиться между 0 и 1. Оптимальный вариант ≈ (√5-1) / 2, его предложил Дональд Кнут.
3. Универсальное хеширование
В универсальном хешировании хеш-функция выбирается случайным образом и не зависит от ключей.
Где применяются
- Когда необходима постоянная скорость поиска и вставки.
- В криптографических приложениях.
- Когда необходима индексация данных.
Примеры реализации хеш-таблиц в Python, Java, Си и C++
Python
# Реализация хеш-таблицы в Python
hashTable = [[],] * 10
def checkPrime(n):
if n == 1 or n == 0:
return 0
for i in range(2, n//2):
if n % i == 0:
return 0
return 1
def getPrime(n):
if n % 2 == 0:
n = n + 1
while not checkPrime(n):
n += 2
return n
def hashFunction(key):
capacity = getPrime(10)
return key % capacity
def insertData(key, data):
index = hashFunction(key)
hashTable[index] = [key, data]
def removeData(key):
index = hashFunction(key)
hashTable[index] = 0
insertData(123, "apple")
insertData(432, "mango")
insertData(213, "banana")
insertData(654, "guava")
print(hashTable)
removeData(123)
print(hashTable)
Java
// Реализация хеш-таблицы в Java
import java.util.*;
class HashTable {
public static void main(String args[])
{
Hashtable<Integer, Integer>
ht = new Hashtable<Integer, Integer>();
ht.put(123, 432);
ht.put(12, 2345);
ht.put(15, 5643);
ht.put(3, 321);
ht.remove(12);
System.out.println(ht);
}
}
Cи
// Реализация хеш-таблицы в Cи
#include <stdio.h>
#include <stdlib.h>
struct set
{
int key;
int data;
};
struct set *array;
int capacity = 10;
int size = 0;
int hashFunction(int key)
{
return (key % capacity);
}
int checkPrime(int n)
{
int i;
if (n == 1 || n == 0)
{
return 0;
}
for (i = 2; i < n / 2; i++)
{
if (n % i == 0)
{
return 0;
}
}
return 1;
}
int getPrime(int n)
{
if (n % 2 == 0)
{
n++;
}
while (!checkPrime(n))
{
n += 2;
}
return n;
}
void init_array()
{
capacity = getPrime(capacity);
array = (struct set *)malloc(capacity * sizeof(struct set));
for (int i = 0; i < capacity; i++)
{
array[i].key = 0;
array[i].data = 0;
}
}
void insert(int key, int data)
{
int index = hashFunction(key);
if (array[index].data == 0)
{
array[index].key = key;
array[index].data = data;
size++;
printf("\n Ключ (%d) вставлен \n", key);
}
else if (array[index].key == key)
{
array[index].data = data;
}
else
{
printf("\n Возникла коллизия \n");
}
}
void remove_element(int key)
{
int index = hashFunction(key);
if (array[index].data == 0)
{
printf("\n Данного ключа не существует \n");
}
else
{
array[index].key = 0;
array[index].data = 0;
size--;
printf("\n Ключ (%d) удален \n", key);
}
}
void display()
{
int i;
for (i = 0; i < capacity; i++)
{
if (array[i].data == 0)
{
printf("\n array[%d]: / ", i);
}
else
{
printf("\n Ключ: %d array[%d]: %d \t", array[i].key, i, array[i].data);
}
}
}
int size_of_hashtable()
{
return size;
}
int main()
{
int choice, key, data, n;
int c = 0;
init_array();
do
{
printf("1.Вставить элемент в хэш-таблицу"
"\n2.Удалить элемент из хэш-таблицы"
"\n3.Узнать размер хэш-таблицы"
"\n4.Вывести хэш-таблицу"
"\n\n Пожалуйста, выберите нужный вариант: ");
scanf("%d", &choice);
switch (choice)
{
case 1:
printf("Введите ключ -:\t");
scanf("%d", &key);
printf("Введите данные-:\t");
scanf("%d", &data);
insert(key, data);
break;
case 2:
printf("Введите ключ, который хотите удалить-:");
scanf("%d", &key);
remove_element(key);
break;
case 3:
n = size_of_hashtable();
printf("Размер хеш-таблицы-:%d\n", n);
break;
case 4:
display();
break;
default:
printf("Неверно введены данные\n");
}
printf("\nПродолжить? (Нажмите 1, если да): ");
scanf("%d", &c);
} while (c == 1);
}
C++
// Реализация хеш-таблицы в C++
#include <iostream>
#include <list>
using namespace std;
class HashTable
{
int capacity;
list<int> *table;
public:
HashTable(int V);
void insertItem(int key, int data);
void deleteItem(int key);
int checkPrime(int n)
{
int i;
if (n == 1 || n == 0)
{
return 0;
}
for (i = 2; i < n / 2; i++)
{
if (n % i == 0)
{
return 0;
}
}
return 1;
}
int getPrime(int n)
{
if (n % 2 == 0)
{
n++;
}
while (!checkPrime(n))
{
n += 2;
}
return n;
}
int hashFunction(int key)
{
return (key % capacity);
}
void displayHash();
};
HashTable::HashTable(int c)
{
int size = getPrime(c);
this->capacity = size;
table = new list<int>[capacity];
}
void HashTable::insertItem(int key, int data)
{
int index = hashFunction(key);
table[index].push_back(data);
}
void HashTable::deleteItem(int key)
{
int index = hashFunction(key);
list<int>::iterator i;
for (i = table[index].begin();
i != table[index].end(); i++)
{
if (*i == key)
break;
}
if (i != table[index].end())
table[index].erase(i);
}
void HashTable::displayHash()
{
for (int i = 0; i < capacity; i++)
{
cout << "table[" << i << "]";
for (auto x : table[i])
cout << " --> " << x;
cout << endl;
}
}
int main()
{
int key[] = {231, 321, 212, 321, 433, 262};
int data[] = {123, 432, 523, 43, 423, 111};
int size = sizeof(key) / sizeof(key[0]);
HashTable h(size);
for (int i = 0; i < size; i++)
h.insertItem(key[i], data[i]);
h.deleteItem(12);
h.displayHash();
}